
Ollama 简介
Ollama 是一个本地运行的大语言模型(LLM)工具平台,允许用户在本地设备上运行和管理大模型,而无需依赖云服务。它支持多种开源模型,并提供了用户友好的接口,非常适合开发者和企业使用。
安装 Ollama
首先,从 Ollama 官网 下载安装包,并按照提示完成安装。
Ollama 命令介绍
Ollama 提供了几个简单易用的命令,基本功能如下:
1 | Usage: |
下载大模型
在 Ollama 官网的 Models 页面 中,可以找到 Ollama 支持的大模型列表。
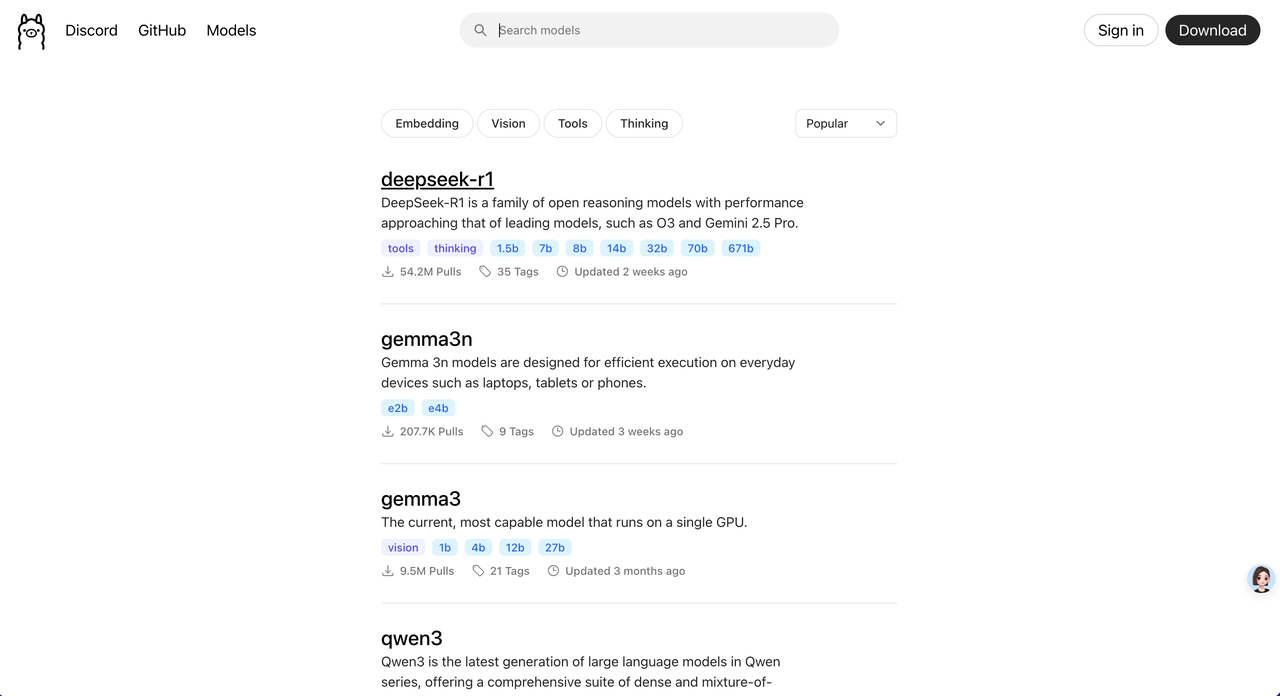
如果没有明确的模型选择,建议使用阿里的 qwen2.5:7b 或 Meta 的 llama3.1:8b。7b 以上的大模型通常能提供更好的对话效果。
查看模型信息
选择一个模型后,点击进入可以查看模型的详细信息。
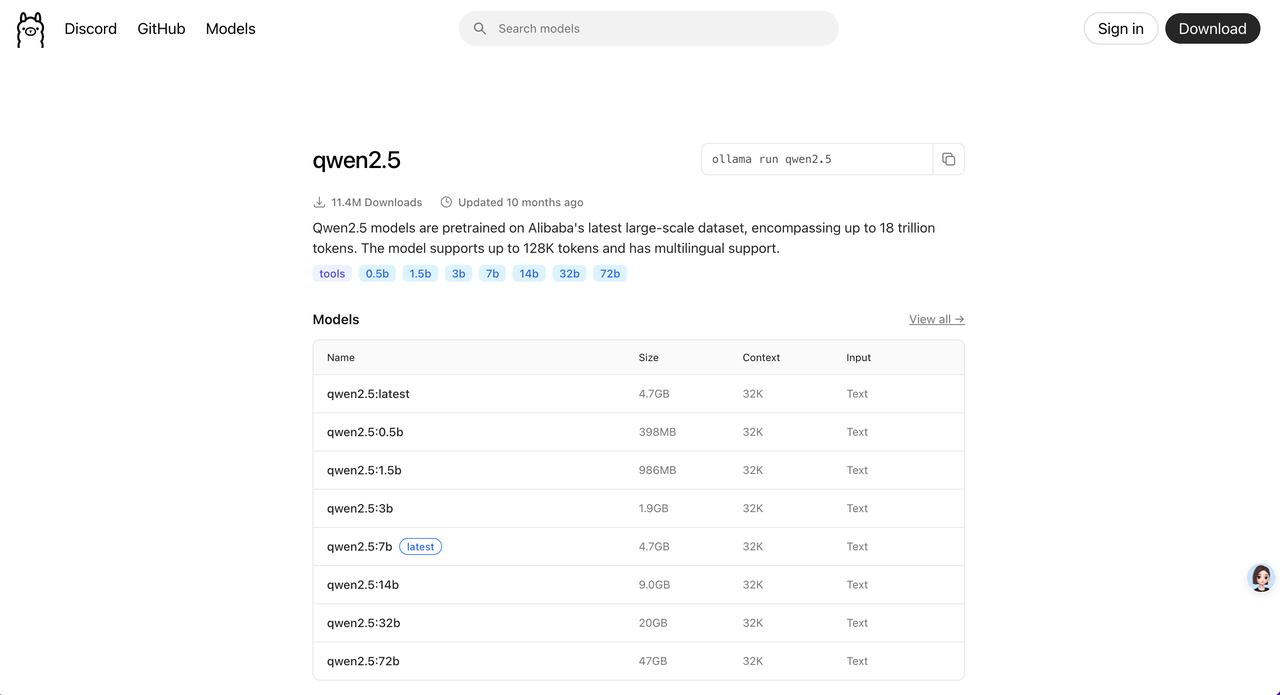
下载模型
使用 ollama run 命令可以在拉取模型后直接进入交互窗口。如果只想下载模型而不进入交互界面,可以使用 ollama pull 命令。
1 | ollama run qwen2.5:7b |
等待模型下载完成后,会直接进入交互界面。
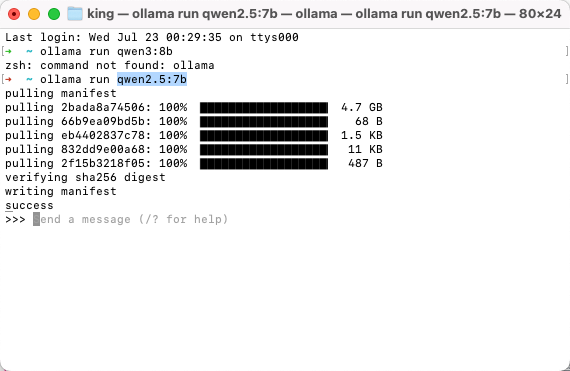
在命令行中输入消息,即可与模型进行交互。

交互窗口命令
在交互窗口中输入 /? 可以查看可用命令。
1 | Available Commands: |
例如,使用 /show 命令查看模型信息:
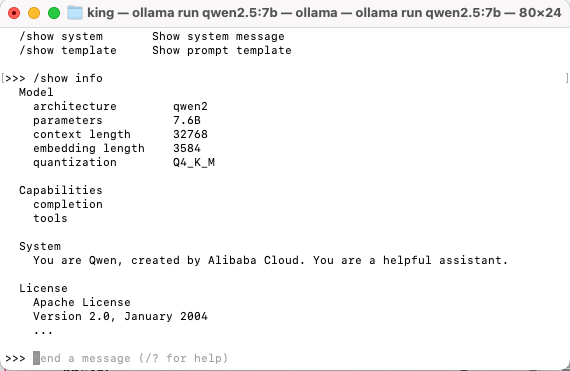
调用 Ollama 接口
Ollama 提供了丰富的 API 接口,供外部调用访问。详细的 接口文档 可以在官方 GitHub 中找到。
| 接口名称 | 接口地址 | 请求方法 | 接口描述 |
|---|---|---|---|
| Generate | /api/generate | POST | 使用提供的模型为给定提示生成响应。 |
| Chat | /api/chat | POST | 使用提供的模型生成聊天中的下一条消息 |
| Create | /api/create | POST | 从 Modelfile 创建一个新的模型。 |
| Tags | /api/tags | GET | 列出本地可提供的型号。 |
| Show | /api/show | POST | 获取指定模型的详细信息。 |
| Copy | /api/copy | POST | 从现有模型创建副本。 |
| Delete | /api/delete | DELETE | 删除模型及其数据。 |
| Pull | /api/pull | POST | 从 Ollama 库中下载指定模型。 |
| Push | /api/push | POST | 将模型上传到模型库。 |
| Embed | /api/embed | POST | 使用指定模型生成嵌入。 |
| ListRunning | /api/ps | POST | 列出当前加载到内存中的模型。 |
| Embeddings | /api/embeddings | POST | 生成嵌入(与 Embed 类似,但可能适用场景不同)。 |
| Version | /api/version | GET | 获取 Ollama 服务的版本号。 |
检查服务
安装 Ollama 后,服务通常会自动启动。为了确保服务正常运行,可以通过以下命令检查:
Ollama 默认端口为 11434,访问地址为 127.0.0.1:11434。
1 | curl http://127.0.0.1:11434 |

如果服务未启动,可以使用以下命令启动:
1 | ollama serve |
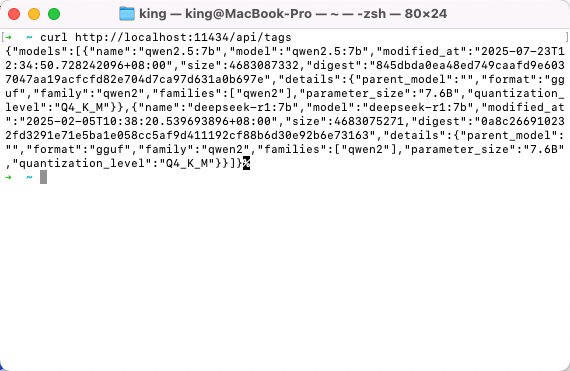
调用模型列表接口
首先,调用一个简单的接口来查询模型列表:
1 | curl http://localhost:11434/api/tags |
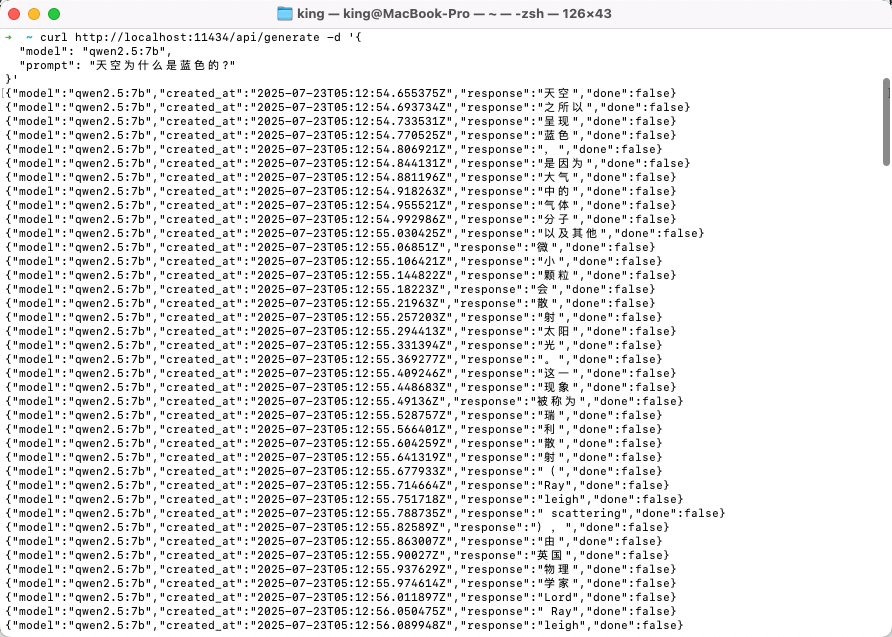
调用生成接口
接下来,调用生成接口来获取模型的响应:
1 | curl http://localhost:11434/api/generate -d '{ |
默认情况下,接口会返回流式数据:
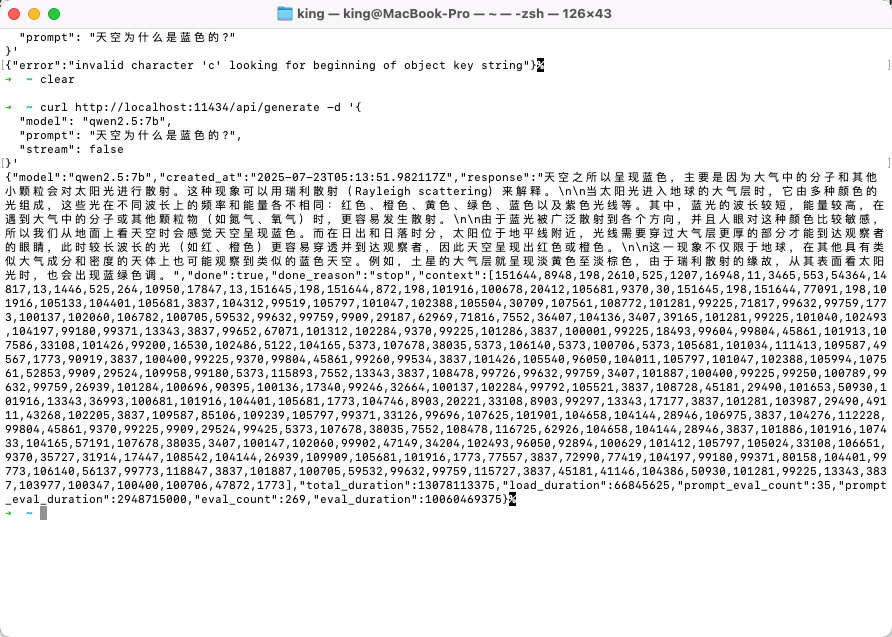
可以通过设置 stream: false 参数,直接返回完整内容:
1 | curl http://localhost:11434/api/generate -d '{ |
使用API远程调用
注意,ollama启动时默认监听在127.0.0.1:11434上,可以通过配置OLLAMA_HOST环境变量修改
1 | export OLLAMA_HOST="0.0.0.0:11434" |
然后可以如上面调用生成接口一样进行远端访问了:
1 | curl http://localhost:11434/api/generate -d '{"model": "qwen2.5:7b","prompt": "what can you do?","stream":false}' |
重点来了,也可以通过通过openai代码接口访问:
1 | from openai import OpenAI |
结果:
1 | ChatCompletion(id='chatcmpl-228', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Task 1:\nSentence: Apple (the technology company), founded by Steve Jobs and located in Cupertino.\nOutput format for Task 1: \n- Entity "Apple" is linked to [Wikipedia page title]: Apple Inc.\n- Entity "Steve Jobs" is linked to [None] as the task only requires linking entities, not individuals.\n\nTask 2:\nSentence: The Eiffel Tower (a famous landmark in Paris) was designed by Gustave Eiffel and completed in 1889.\nOutput format for Task 2:\n- Entity "Eiffel Tower" is linked to [Wikipedia page title]: Eiffel Tower\n- Entity "Gustave Eiffel" is linked to [None]\n\nTask 3: \nSentence: The Great Barrier Reef (the largest coral reef system in the world) spans over 2,000 kilometers.\nOutput format for Task 3:\n- Entity "Great Barrier Reef" is linked to [Wikipedia page title]: Great Barrier Reef\n\nNote that some entities might not have a corresponding Wikipedia article or may be ambiguous. In such cases, you should output None as instructed in the task description.\n\nThese tasks are of classification type since they require linking named entities to their respective Wikipedia pages (or determining if there is no suitable link).', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))], created=1753247977, model='qwen2.5:7b', object='chat.completion', service_tier=None, system_fingerprint='fp_ollama', usage=CompletionUsage(completion_tokens=266, prompt_tokens=109, total_tokens=375, completion_tokens_details=None, prompt_tokens_details=None)) |
在gops-agent里测试
模型信息:
1 | LLM_API_KEY= "sk-ollama" |
初始化:
1 | 全局 LLM 实例 |
测试结果:
1 | 上海天气怎么样,如果还不错的话,帮我计算下50乘4加6 |